完全分布式搭建
在前面单机版搭建成功的基础上:
修改网卡地址并重启网卡:

重启网卡 service newtork restart
设置主机名: hostnamectl set-hostname bigdata167
配置hosts vi /etc/hosts 添加配置地址 然后reboot
重新生成钥匙:
(最后是从快照克隆的,因此需要重新生成钥匙,同时也要修改IP等信息)

拷贝钥匙 ssh-copy-id bigdata166 (因为配置了IP所以可以输入密码拷贝) 测试成功

配置hadoop相关配置
修改secondarynamenode的地址为167 hdfs-site.xml文件

同级目录下修改slaves文件

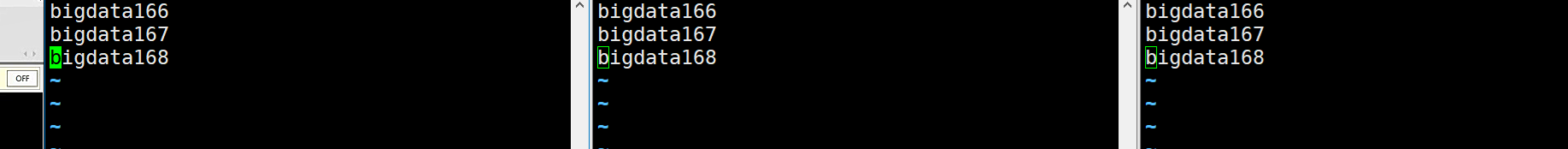
重新格式化(删除原数据)
可以查看到以下元数据
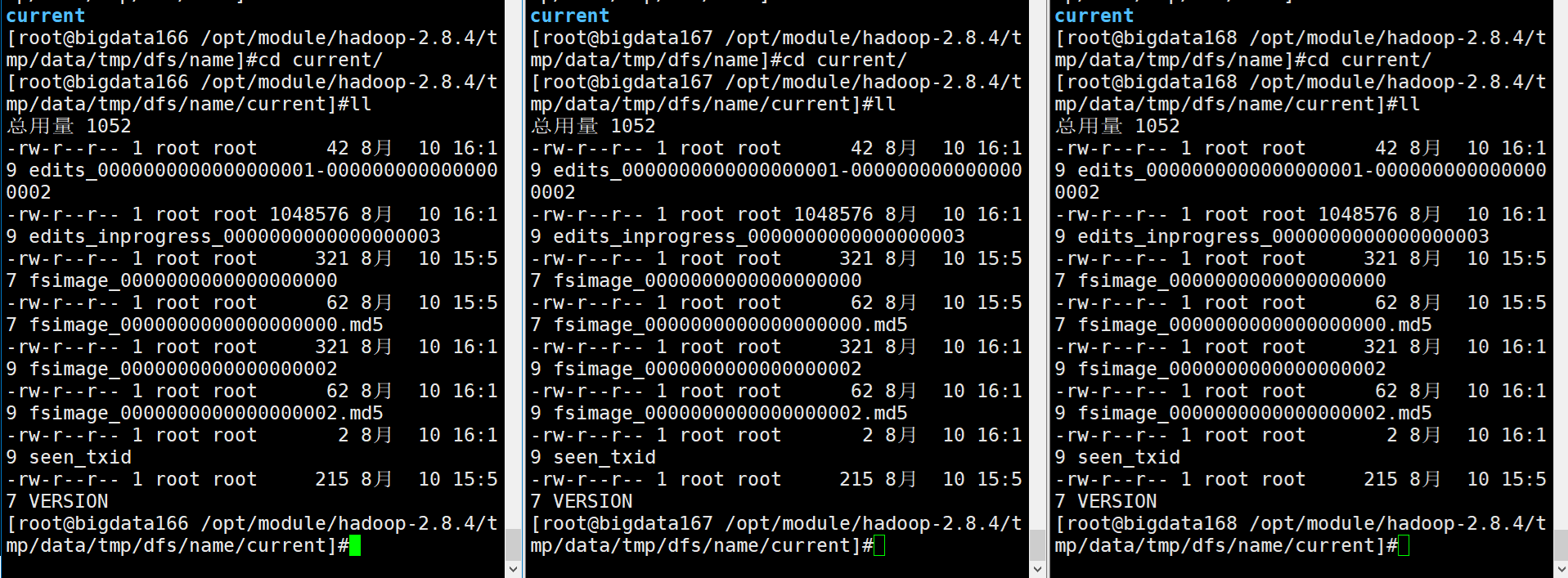
删除三台data目录(中的内容,删除data也可以)

删除三台logs目录(中的内容,删除logs也可以)

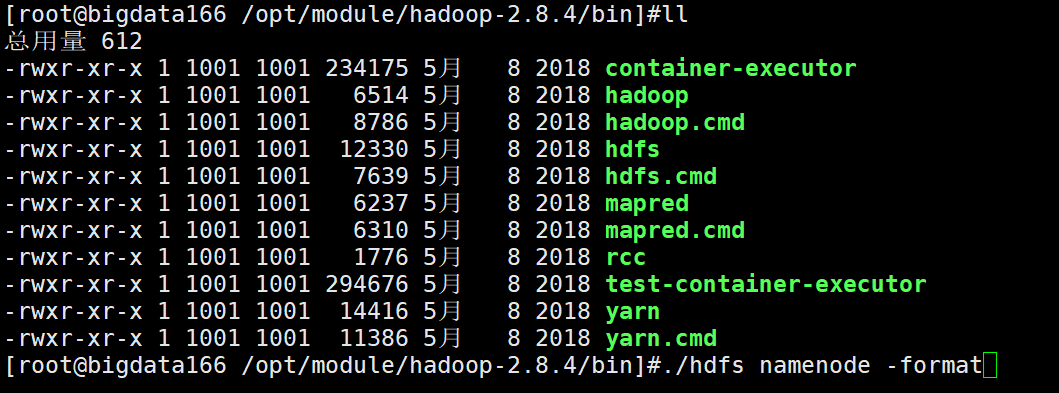
交给主节点完成命令 重新格式化(只在主节点) 此次将角色分配到每一个节点当中
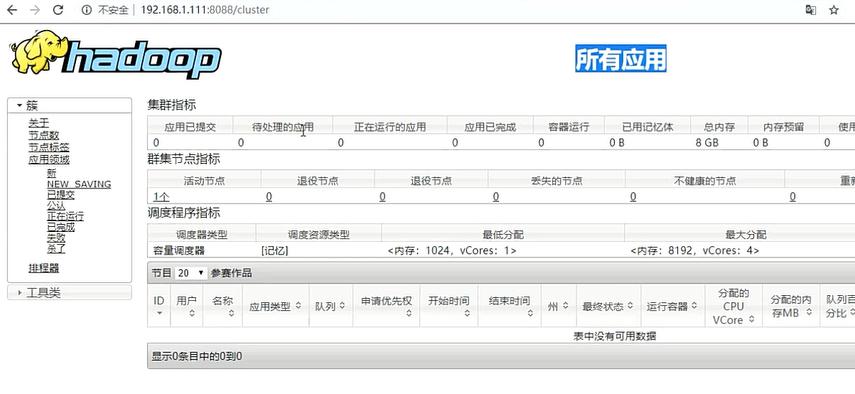
启动hdfs
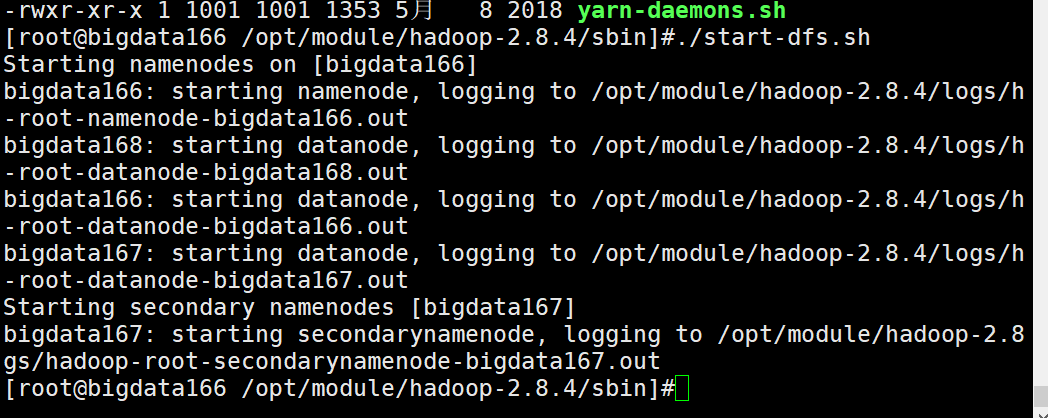
查看配置完成

有坑:
2.8.4文件夹下面的tmp目录某些文件没删除,导致启动时datanode的集群id和anmenode的集群id不同,因此全部出现没有启动datanode的现象:
现象:
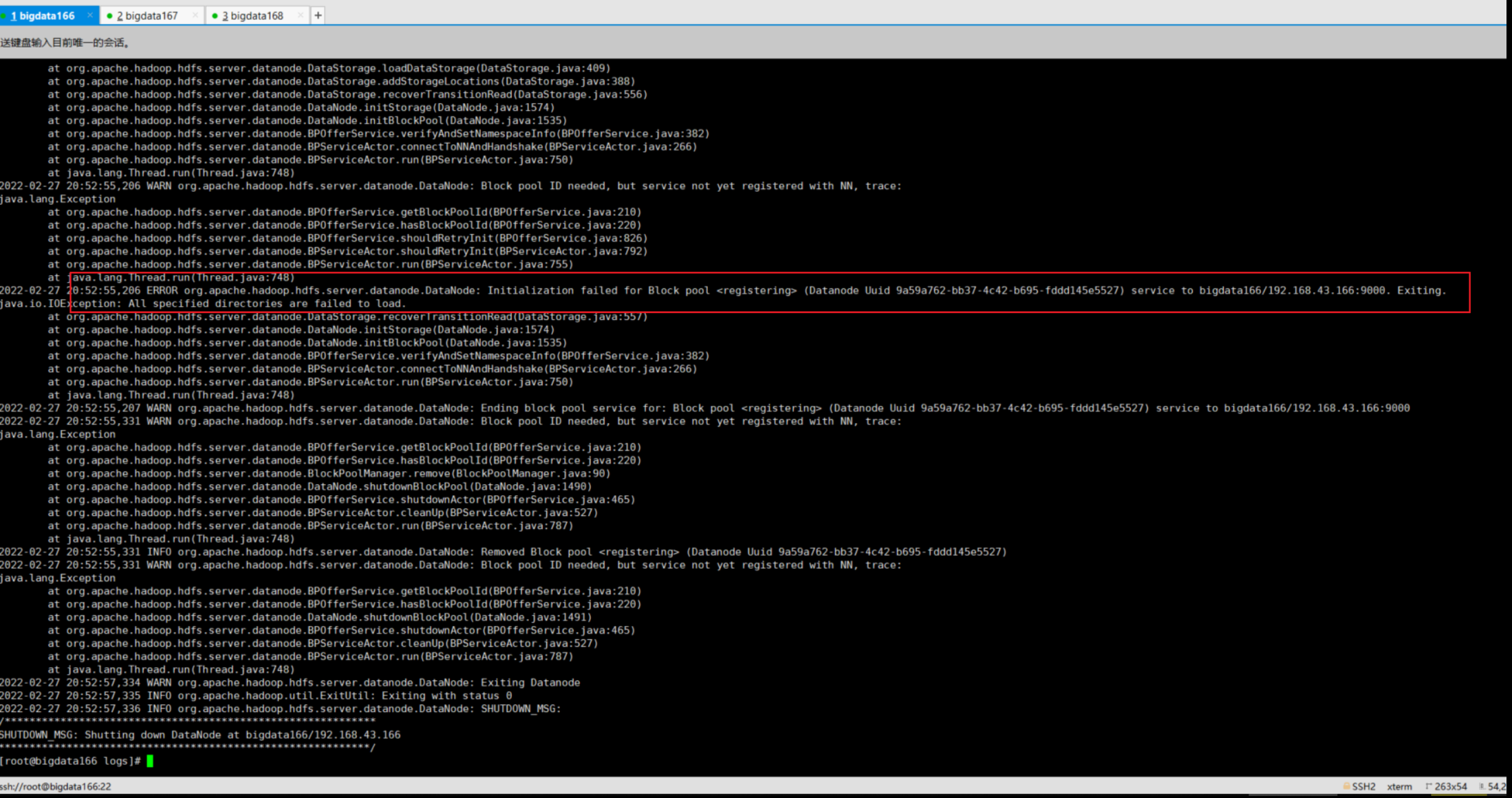
解决方案:删除tmp里面的current文件夹中的内容,然后重新格式化
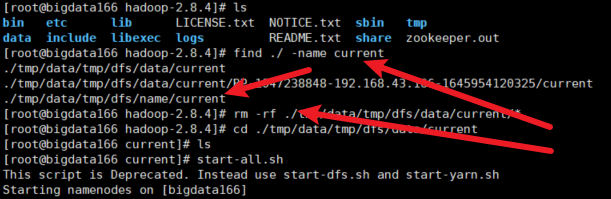
详见:https://blog.51cto.com/hsbxxl/2066487
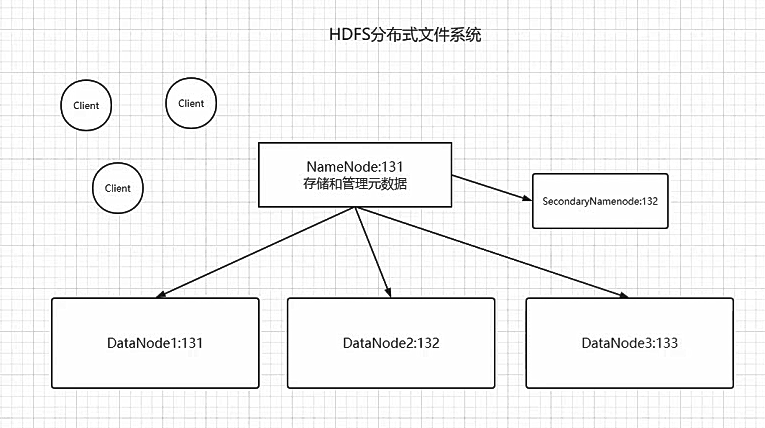
架构解析:
启动yarn

yarn结构:
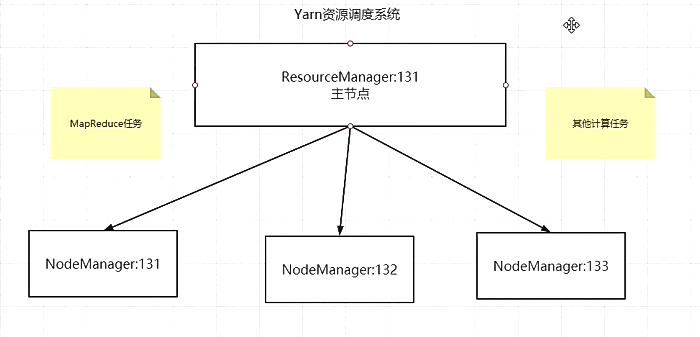
配置环境变量:/opt/module/hadoop-2.8.4



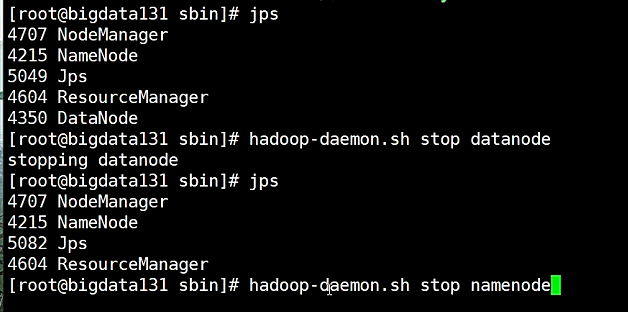
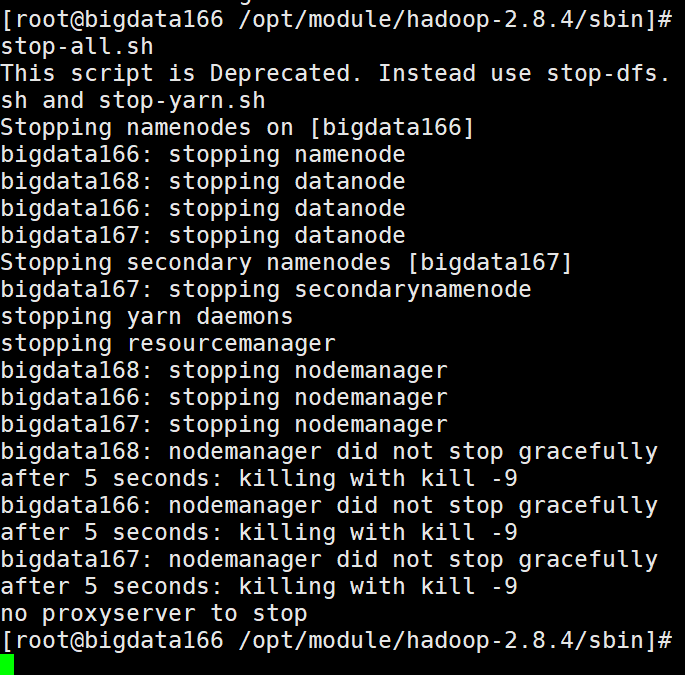
停止 stop-all.sh
其它
单独启停